
یادگیری ماشین تحت نظارت (supervised machine learning) چگونه کار می کند؟
یادگیری ماشین تحت نظارت، یکی از روشهای رایج در یادگیری ماشین است که به ماشینها اجازه میدهد از طریق دادههای برچسبگذاری شده، به طور خودکار یاد بگیرند. در این روش، الگوریتمها با مجموعهای از دادهها که ورودی و خروجی آنها مشخص است، آموزش داده میشوند. به عنوان مثال، الگوریتمی برای تشخیص تصاویر گربه، با مجموعهای از تصاویر گربه و سگ آموزش داده میشود.
به زبان ساده تر یادگیری ماشین تحت نظارت، روشی در یادگیری ماشینی و کاربرد آن در صنعت است که به الگوریتمها اجازه میدهد از طریق دادههای برچسبگذاری شده، به طور خودکار یاد بگیرند.
پس از آموزش، الگوریتم میتواند با تجزیه و تحلیل دادههای جدید، خروجی آنها را پیشبینی کند. به عنوان مثال، الگوریتم تشخیص گربه میتواند با دیدن تصویر جدیدی از یک حیوان، تشخیص دهد که آن حیوان گربه است یا سگ.
برای خدمات یادگیری ماشین، بخوانید.
یادگیری ماشین تحت نظارت، گامی مهم در مسیر هوش مصنوعی
هوش مصنوعی، به عنوان رباتها یا کامپیوترهایی که میتوانند مانند انسانها فکر و عمل کنند، از دیرباز ذهن بشر را به خود مشغول کرده است اما در این میان، یادگیری ماشین به عنوان زیرشاخهای از هوش مصنوعی، نقشی کلیدی در تحقق این رویا ایفا میکند.
یادگیری ماشین تحت نظارت در طیف وسیعی از کاربردهای هوش مصنوعی، از جمله تشخیص چهره، پردازش زبان طبیعی، و تشخیص پزشکی، مورد استفاده قرار میگیرد. این روش به ماشینها اجازه میدهد تا بدون نیاز به برنامهنویسی صریح، به طور خودکار از دادهها یاد بگیرند و وظایف پیچیدهای را انجام دهند.
با وجود مزایای فراوان، یادگیری ماشین تحت نظارت به دادههای برچسبگذاری شده زیادی نیاز دارد که تهیه آنها میتواند دشوار و پرهزینه باشد. همچنین، این روش در برابر دادههای نادرست و گمراهکننده آسیبپذیر است.
با وجود این چالشها، یادگیری ماشین تحت نظارت به عنوان ابزاری قدرتمند در مسیر توسعه هوش مصنوعی شناخته میشود و گامی مهم در جهت تحقق رویای ماشینهای هوشمند به حساب میآید.
در یادگیری ماشین تحت نظارت، مدلها با استفاده از مجموعه دادههای برچسبگذاری شده آموزش داده میشوند، جایی که مدل در مورد هر نوع داده میآموزد. پس از تکمیل فرآیند آموزش، مدل بر اساس داده های آزمون- تست (زیرمجموعه ای از مجموعه آموزشی) آزمایش می شود سپس خروجی را پیش بینی می کند.
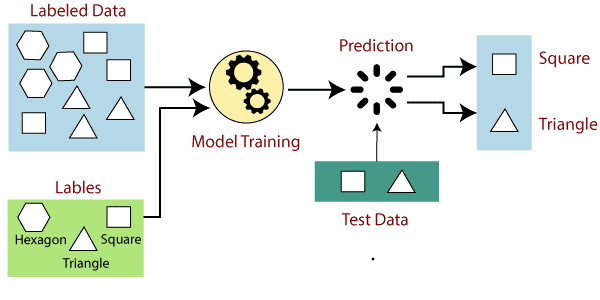
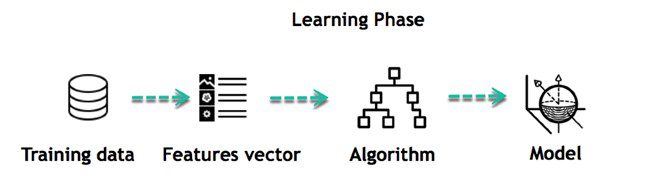
کاربرد های یادگیری ماشین تحت نظارت
یادگیری ماشین تحت نظارت یکی از انواع یادگیری ماشین است که در آن مدل با استفاده از دادههای برچسبزده آموزش میبیند. دادههای برچسبزده دادههایی هستند که دارای یک خروجی صحیح یا مطلوب هستند. مدل با تجزیه و تحلیل دادههای برچسبزده یاد میگیرد که چگونه خروجی صحیح را برای ورودیهای جدید پیشبینی کند.
یادگیری ماشین تحت نظارت برای طیف گستردهای از کاربردها استفاده میشود، از جمله:
۱. رگرسیون (Regression)
در رگرسیون، یک مقدار خروجی واحد با استفاده از داده های آموزشی تولید می شود. این مقدار یک تفسیر احتمالی است که پس از در نظر گرفتن قدرت همبستگی بین متغیرهای ورودی مشخص می شود. رگرسیون از مجموعه داده های برچسب دار یاد می گیرد و سپس قادر به پیش بینی یک خروجی با ارزش پیوسته برای داده های جدید داده شده به الگوریتم است.به عنوان مثال، رگرسیون می تواند به پیش بینی قیمت یک خانه بر اساس محل، اندازه و غیره کمک کند.
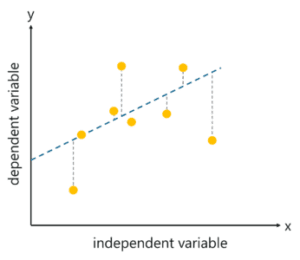
رگرسیون خطی
این الگوریتم فرض میکند که یک رابطه خطی بین دو متغیر ورودی (X) و خروجی (Y) از دادههایی که از آنها آموخته است وجود دارد. متغیر ورودی را متغیر مستقل و متغیر خروجی را متغیر وابسته می نامند. هنگامی که دادههای دیده نشده به الگوریتم ارسال میشوند، از تابع استفاده میکند، ورودی را محاسبه میکند و به یک مقدار پیوسته برای خروجی لحاظ میکند.
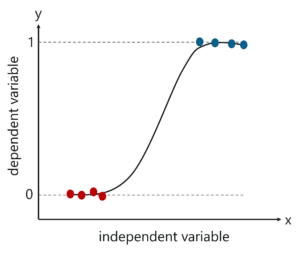
رگرسیون لجستیک
این الگوریتم مقادیر گسسته ای را برای مجموعه متغیرهای مستقلی که به آن ارسال شده است پیش بینی می کند. الگوریتم احتمال داده های جدید را پیش بینی می کند و بنابراین خروجی آن بین محدوده ۰ و ۱ قرار دارد.
انواع رگرسیون:
۲. طبقه بندی (Classification)
این شامل گروه بندی داده ها به کلاس ها است. هنگامی که در طبقه بندی ، داده های ورودی را در دو کلاس مجزا برچسب گذاری می کشود پس به آن طبقه بندی باینری می گویند. طبقه بندی چندگانه به معنای دسته بندی داده ها به بیش از دو کلاس است. خروجی یکی از کلاس ها خواهد بود و نه عددی که در رگرسیون بود. درختان تصمیم بر اساس مقادیر ویژگی طبقه بندی می شوند.
آنها از روش اطلاعات بدست آمده استفاده می کنند و متوجه می شوند که کدام ویژگی مجموعه داده بهترین اطلاعات را ارائه می دهد، آن را به عنوان گره ریشه می سازند تا زمانی که بتوانند هر نمونه از مجموعه داده را طبقه بندی کنند. هر شاخه در درخت تصمیم یک ویژگی از مجموعه داده را نشان می دهد اما باید بدانید که آنها یکی از پرکاربردترین الگوریتم ها برای طبقه بندی هستند.
۳. مدیریت ریسک
مدیریت ریسک شامل پیش بینی احتمال وقوع یک رویداد نا مطلوب است. به عنوان مثال، یک مدل مدیریت ریسک میتواند برای پیش بینی احتمال اینکه یک مشتری اعتباری بدهی خود را پرداخت نکند استفاده شود.
انواع الگوریتم های یادگیری ماشین تحت نظارت
چندین نوع الگوریتم یادگیری ماشین تحت نظارت وجود دارد که هر کدام مزایا و معایب خاص خود را دارند اما برخی از الگوریتمهای رایج عبارتند از:
نایو بیز (Naive Bayesian Model)
مدل نایو بیز برای مجموعه بزرگی از داده ها استفاده می شود. این روشی برای تخصیص برچسب های کلاس با استفاده از یک گراف چرخه ای است و الگوریتم فرض می کند که ویژگی های مجموعه داده همه مستقل از یکدیگر هستند. نمودار نایو بیز شامل یک گره والد و چندین گره فرزند است. و هر گره فرزند مستقل و جدا از والد فرض می شود.
مدل های درخت تصمیم (Decision Trees)
درخت تصمیم یک مدل فلوچارت مانند است که شامل عبارات کنترل شرطی است که شامل تصمیمات و پیامدهای احتمالی آنها می شود. خروجی مربوط به برچسب گذاری داده های پیش بینی نشده است. در نمایش درختی، گره های برگ با برچسب های کلاس مطابقت دارند و گره های داخلی نشان دهنده ویژگی ها هستند. درخت تصمیم می تواند برای حل مسائل با ویژگی های گسسته و همچنین توابع بولی استفاده شود.
مدلهای خطی
مدل های خطی ساده ترین نوع الگوریتم های یادگیری ماشین تحت نظارت هستند و آنها معمولاً برای مسائل طبقه بندی یا رگرسیون استفاده میشوند.
مدل شبکههای عصبی
شبکههای عصبی الگوریتم های پیچیده ای هستند که میتوانند برای طیف گسترده ای از مسائل طبقه بندی و رگرسیون استفاده شوند. آنها میتوانند پیچیدگی های داده ها را به خوبی مدل کنند.
ماشینهای بردار پشتیبان (SVM)
الگوریتمهای SVM بر اساس تئوری یادگیری آماری هستند. آنها از توابع Kernal استفاده می کنند که یک مفهوم مرکزی برای اکثر وظایف یادگیری است. این الگوریتم ها یک ابر صفحه ایجاد می کنند که برای طبقه بندی دو کلاس از یکدیگر استفاده می شود.
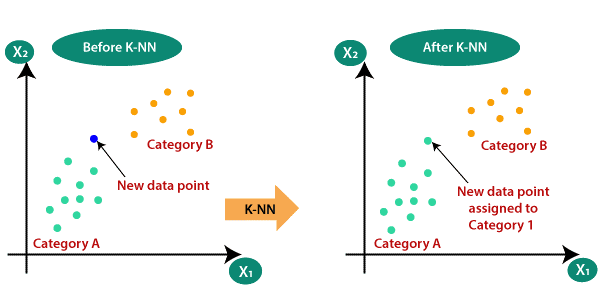
نزدیک ترین همسایه (K-Nearest Neighbour )
یکی از ساده ترین الگوریتم های یادگیری ماشین بر اساس تکنیک یادگیری نظارت شده است. الگوریتم K-NN شباهت بین مورد/ داده جدید و موارد موجود را فرض می کند و مورد جدید را در دسته ای قرار می دهد که بیشترین شباهت را به دسته های موجود دارد. الگوریتم KNN در مرحله آموزش فقط مجموعه داده را ذخیره می کند و زمانی که داده های جدیدی دریافت می کند، آن داده ها را در دسته ای طبقه بندی می کند که بسیار شبیه به داده های جدید است.
اهمیت کیفیت دادهها در یادگیری ماشین تحت نظارت
در یادگیری ماشین تحت نظارت، کیفیت دادههای برچسبگذاریشده نقش تعیینکنندهای در عملکرد نهایی مدل دارد. اگر دادهها ناقص، نامتوازن یا دارای برچسبهای اشتباه باشند، حتی پیشرفتهترین الگوریتمها نیز نمیتوانند خروجی دقیقی ارائه دهند. به همین دلیل، مرحله پیشپردازش دادهها شامل پاکسازی، نرمالسازی و بررسی صحت برچسبها، یکی از حیاتیترین بخشهای پیادهسازی مدلهای یادگیری تحت نظارت به شمار میرود. هرچه دادهها واقعیتر و نمایندهتر از مسئله باشند، مدل آموزشدیده توانایی تعمیم به دادههای جدید را بهتر خواهد داشت.
نقش یادگیری ماشین تحت نظارت در تصمیمگیریهای هوشمند سازمانی
امروزه سازمانها از یادگیری ماشین تحت نظارت برای پشتیبانی از تصمیمگیریهای کلان و عملیاتی استفاده میکنند. مدلهای پیشبینی مبتنی بر دادههای تاریخی میتوانند روند فروش، رفتار مشتریان یا احتمال بروز ریسکهای مالی را با دقت بالایی تحلیل کنند. این رویکرد دادهمحور باعث میشود تصمیمها بهجای حدس و تجربه صرف، بر اساس تحلیلهای آماری و الگوهای واقعی اتخاذ شوند. در نتیجه، یادگیری ماشین تحت نظارت به ابزاری کلیدی در تحول دیجیتال سازمانها و افزایش بهرهوری تبدیل شده است.
چالشهای یادگیری ماشین تحت نظارت
یادگیری ماشین تحت نظارت چالش های خاص خود را دارد. یکی از چالش ها این است که داده های برچسب زده اغلب گران یا دشوار برای جمع آوری هستند. چالش دیگر این است که الگوریتم های یادگیری ماشین تحت نظارت میتوانند نسبتاً پیچیده باشند و تنظیم آنها میتواند دشوار باشد.
نتیجه گیری
یادگیری ماشین تحت نظارت یک ابزار قدرتمند است که می توان از آن برای طیف گسترده ای از کاربرد ها استفاده کرد، پس با این حال، مهم است که چالش های این رویکرد را درک کنید و از الگوریتم های مناسب برای مشکل خاص خود استفاده کنید جهت سوالات بیشتر با مشاوران نظم آران تماس بگیرید.
سوالات متداول
- یادگیری ماشین تحت نظارت چیست؟
یادگیری ماشین تحت نظارت روشی است که در آن مدل ها با استفاده از داده های برچسب گذاری شده آموزش می بینند تا بتوانند خروجی داده های جدید را پیش بینی کنند. - تفاوت یادگیری ماشین تحت نظارت با بدون نظارت چیست؟
در یادگیری تحت نظارت از داده های برچسب گذاری شده استفاده می شود، اما در یادگیری بدون نظارت الگوریتم ها به دنبال کشف الگوها در داده های بدون برچسب هستند. - کاربردهای یادگیری ماشین تحت نظارت چیست؟
کاربردها شامل تشخیص چهره، پردازش زبان طبیعی، پیش بینی قیمت ها، تشخیص بیماری ها، مدیریت ریسک و سیستم های توصیه گر می شود. - چرا یادگیری ماشین تحت نظارت در هوش مصنوعی اهمیت دارد؟
زیرا پایه بسیاری از کاربردهای عملی هوش مصنوعی مثل تشخیص تصویر و گفتار بر اساس یادگیری تحت نظارت بنا شده است. - چالش های اصلی یادگیری ماشین تحت نظارت چیست؟
چالش ها شامل جمع آوری داده های مناسب، هزینه بر بودن برچسب گذاری داده ها و پیچیدگی در تنظیم الگوریتم ها است.