مفهوم یادگیری ماشین (machine learning)
یادگیری ماشین یکی از شاخه های کلیدی هوش مصنوعی است که به سیستم ها امکان می دهد بدون برنامه ریزی صریح، از داده ها بیاموزند و پیشبینی یا تصمیمگیری کنند. در واقع، الگوریتم یادگیری ماشین داده ها را دریافت کرده و با کشف الگوها، روابط و وابستگی ها، یک مدل پیش بینی گر یا تحلیل گر ایجاد می کند. شرکت ها و سازمان ها روزانه حجم عظیمی از داده ها تولید می کنند و الگوریتم های یادگیری ماشین این داده ها را به دانش کاربردی تبدیل می کنند.
بیشتر بخوانید: فرآیند کریسپ (CRISP) -روش شناسی کریسپ و چرخه کریسپ
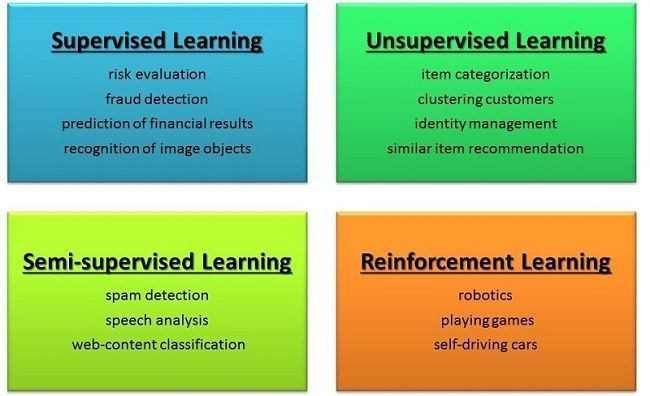
انواع الگوریتم های یادگیری ماشین
مدل ها و الگوریتم های یادگیری ماشین به چهار دسته اصلی تقسیم می شوند:
یادگیری نظارت شده (Supervised Learning)
انواع مدل های یادگیری ماشین ، فرآیند یادگیری الگوریتم از مجموعه داده های آموزشی را می توان به عنوان معلمی در نظر گرفت که بر فرآیند یادگیری نظارت می کند. ما پاسخ های صحیح را می دانیم، الگوریتم به طور مکرر روی داده های آموزشی پیش بینی می کند و توسط معلم تصحیح می شود. یادگیری زمانی متوقف می شود که الگوریتم به سطح قابل قبولی از عملکرد دست یابد. در یادگیری نظارت شده، ورودی های واضحی را برای الگوریتم یادگیری ماشین ارائه می دهید. الگوریتم می داند که از داده ها و نتیجه گیری های مورد انتظار از آن چه چیزی را یاد بگیرد. برچسب گذاری داده ها برای ایجاد یک مدل نظارت شده مهم است. شرکت ها مجموعه داده های بزرگ را به صورت روزانه جمع آوری می کنند. برچسبگذاری این مجموعه دادهها برای آسانتر کردن کار مدل یادگیری ماشینی
(machine learning) است. الگوریتمهای یادگیری نظارت شده سعی میکنند روابط و وابستگیهای بین خروجی، پیشبینی هدف و ویژگیهای ورودی را مدلسازی کنند تا بتوانیم مقادیر خروجی دادههای جدید را بر اساس آن روابطی که از مجموعه دادههای قبلی آموخته است، پیشبینی کنیم.
یادگیری نظارت شده را می توان بیشتر به رگرسیون و طبقه بندی دسته بندی کرد که برای سیستم های توصیه گر و پیش بینی سری های زمانی کاربرد داد.
۱- رگرسیون در ارتباط با سری های زمانی که خروجی آن به صورت پیوسته است. هدف نهایی الگوریتم رگرسیون ترسیم بهترین خط یا منحنی بین داده ها است. سه معیار اصلی که برای ارزیابی مدل رگرسیون آموزش دیده استفاده می شود، واریانس، انحراف و خطا هستند.
۲- طبقه بندی که خروجی ها به صورت دسته ای و گسسته است و اساساً مجموعه ای از داده ها را به کلاس ها طبقه بندی می کند.
برخی از نمونه های محبوب الگوریتم های یادگیری ماشینی (machine learning) نظارت شده عبارتند از:
رگرسیون خطی برای مسائل رگرسیون.
جنگل تصادفی برای مسائل طبقه بندی و رگرسیون.
پشتیبانی از ماشین های برداری برای مسائل طبقه بندی.

یادگیری بدون نظارت (unsupervised Learning)
در یادگیری بدون نظارت فقط به داده ورودی دسترسی دارید و هیچ متغیر خروجی مرتبطی ندارید. هدف یادگیری بدون نظارت مدل سازی ساختار یا توزیع داده ها به منظور کسب و استخراج بیشتر اطلاعات از داده ها است. در یادگیری بدون نظارت بر خلاف یادگیری نظارت شده، هیچ پاسخ صحیحی وجود ندارد و معلمی وجود ندارد. الگوریتمها برای کشف و ارائه ساختار در دادهها به تدبیر خود عمل می کنند.
الگوریتم های یادگیری بدون نظارت برای خوشه بندی داده و قواعد انجمنی بر اساس ویژگی های موجود استفاده می شود.
- خوشه بندی: درخوشه بندی می خواهید گروه بندی داده ها را کشف کنید، مانند گروه بندی مشتریان با رفتار خرید.
- قواعد انجمنی: میخواهید قوانینی را کشف کنید که بخشهای بزرگی از دادههای شما را توصیف میکنند، مانند افرادی که محصول/ سرویس X را میخرند نیز تمایل به خرید محصول/ سرویس Y دارند. قوانین انجمن به شما اجازه می دهد تا ارتباط بین اشیاء داده در پایگاه داده های بزرگ ایجاد کنند. این تکنیک در مورد کشف روابط بین متغیرها در پایگاه های داده است.
برخی از نمونه های محبوب الگوریتم های یادگیری بدون نظارت عبارتند از:
خوشه بندی سلسله مراتبی
K-به معنای خوشه بندی است
K-NN (k نزدیکترین همسایه)
تجزیه و تحلیل مؤلفه های اصلی
تجزیه مقدار منفرد
تجزیه و تحلیل اجزای مستقل

خوشه بندی سلسله مراتبی
خوشه بندی سلسله مراتبی الگوریتمی است که سلسله مراتبی از خوشه ها را ایجاد می کند. با تمام داده هایی که به یک خوشه اختصاص داده شده اند شروع می شود. در اینجا، دو خوشه نزدیک در یک خوشه قرار می گیرند. این الگوریتم زمانی به پایان می رسد که تنها یک خوشه باقی بماند.
K-means
این نوع خوشه بندی K-means با تعداد ثابتی از خوشه ها شروع می شود. تمام داده ها را به تعداد خوشه ها تخصیص می دهد. این روش خوشه بندی به تعداد خوشه های K به عنوان ورودی نیاز ندارد. این روش با استفاده از اندازه گیری فاصله، تعداد خوشه ها ( در هر تکرار) را با ادغام فرآیند کاهش می دهد. در نهایت، ما یک خوشه بزرگ داریم که شامل تمام اشیاء است.
ک- نزدیکترین همسایگان
K- نزدیکترین همسایه ساده ترین طبقه بندی کننده های یادگیری ماشین است. با سایر تکنیک های یادگیری ماشین تفاوت دارد، زیرا مدلی تولید نمی کند. این یک الگوریتم ساده است که تمام موارد موجود را ذخیره می کند و نمونه های جدید را بر اساس معیار تشابه طبقه بندی می کند.
یادگیری ماشین نیمه نظارت شده (semi- supervised learning)
مسائلی که در آنها مقدار زیادی داده ورودی دارید و فقط برخی از داده ها دارای برچسب هستند، یادگیری نیمه نظارتی نامیده می شوند. در حقیقت یادگیری نیمه نظارت شده بین یادگیری نظارت شده و بدون نظارت قرار می گیرد. می توانید از تکنیک های یادگیری بدون نظارت برای کشف و یادگیری ساختار در متغیرهای ورودی استفاده کنید. همچنین میتوانید از تکنیکهای یادگیری نظارتشده برای انجام بهترین پیشبینیها برای دادههای بدون برچسب استفاده کنید، آن دادهها را به عنوان دادههای آموزشی به الگوریتم یادگیری نظارتشده برگردانید و از مدل برای پیشبینی دادههای بدون نظرت جدید استفاده کنید.
یادگیری تقویتی (reinforcement learning)
هیچ الگوریتم یادگیری ماشینی 100٪ دقیق نیست. سطح دقت بستگی به مجموعه داده ای دارد که الگوریتم را با آن آموزش می دهید. این بدان معناست که پس از آموزش یک الگوریتم، مجموعه داده های جدیدی در دسترس خواهد بود. این مجموعه داده ها ممکن است این پتانسیل را داشته باشند که دقت مدل شما را به میزان قابل توجهی بهبود بخشند. برای این نوع سناریو می توانید از یادگیری تقویتی استفاده کنید. یادگیری تقویتی مفهوم به روز رسانی الگوریتم در حین تولید است. مدل های یادگیری تقویتی می توانند بر اساس ورودی های جدید بازآموزی شود.
انواع داده های بدون ساختار
بسیاری از سازمانهای امروزه تلاش میکنند تا حجم رو به رشد دادههای بدون ساختار را مدیریت کنند. یادگیری ماشینی ساختار و معنی مناسب را به داده ها می دهد تا به تصمیم گیری ، سرمایه گذاری و تعیین استراتژی کمک کند.
۱- ساختار یافته(Structured data)
۲- غیرساختار یافته(Unstructured data )
۳- نیمه ساختار یافته (Semi-structured data)
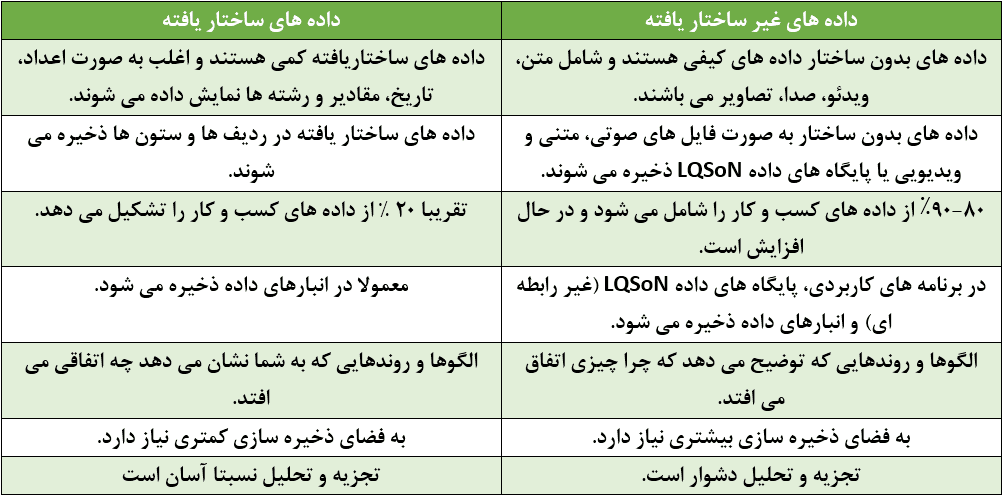
داده های ساختار یافته چیست؟
داده های ساختاریافته کمی(عددی)، بسیار سازمان یافته و با استفاده از نرم افزار تجزیه و تحلیل داده ها قابل بررسی و تجزیه و تحلیل هستند. این نوع از داده ها طراحی منظمی دارند و در ردیفها، ستونها و جداول قرار میگیرند. داده های ساختار یافته برای سازماندهی اولیه و محاسبات کمی عالی هستند، اما در تعیین پارامتر ها انعطاف پذیری لازم را ندارند. و هم چنین می تواند بیش کافی را به افراد ندهد.
داده های غیر ساختار یافته چیست؟
داده های بدون ساختار اطلاعاتی هستند که سازماندهی خاصی ندارند و در چارچوب تعریف شده قرار نمی گیرند. نمونههایی از دادههای بدون ساختار عبارتند از: صدا، ویدئو، تصاویر و انواع متن: گزارشها، ایمیلها، پستهای رسانههای اجتماعی.
یافتن بینش در دادههای بدون ساختار آسان نیست، اما زمانی که دادههای متنی به درستی تجزیه و تحلیل شوند، میتوانند برای استخراج نتایج کیفی، مانند نظرات مشتریان، یا سازماندهی دادههای کسبوکار بسیار ارزشمند باشند.

داده های نیمه ساختاریافته چیست؟
داده های نیمه ساختار یافته به داده هایی گفته می شود که با یک مدل داده مطابقت ندارند اما دارای ساختاری هستند. داده هایی هستند که در یک پایگاه داده منطقی قرار نمی گیرند، اما دارای برخی ویژگی های سازمان یافته هستند که تجزیه و تحلیل آن را آسان تر می کند.
ویژگی های داده های نیمه ساختار یافته:
- داده ها با یک مدل داده مطابقت ندارند اما دارای ساختار هستند.
- داده ها را نمی توان در قالب سطر و ستون مانند پایگاه داده ذخیره کرد
- داده های نیمه ساختاریافته حاوی برچسب ها و عناصری هستند که برای گروه بندی و توصیف نحوه ذخیره داده ها استفاده می شود.
- موجودیت های مشابه با هم گروه بندی شده و در یک سلسله مراتب سازماندهی می شوند
- موجودیت های یک گروه ممکن است دارای ویژگی های یکسان باشند یا نداشته باشند
- اندازه و نوع ویژگی های یکسان در یک گروه ممکن است متفاوت باشد
- به دلیل نداشتن ساختار مشخص، نمی توان به راحتی توسط برنامه های کامپیوتری از آن استفاده کرد. با برخی از فرآیندها، می توانیم آنها را در پایگاه داده رابطه ای ذخیره کنیم.
جمع بندی
الگوریتم های یادگیری ماشین به کسب و کارها کمک می کنند تا از دل داده های خام، الگوهای ارزشمند استخراج کنند و تصمیمگیری های دقیق تری داشته باشند. از یادگیری نظارت شده برای پیش بینی و طبقه بندی گرفته تا یادگیری تقویتی برای تصمیم گیری های پویا، هر کدام نقش حیاتی در دنیای امروز دارند برای سوالات بیشتر با مشاوران نظم آران تماس بگیرید.
سوالات متداول
الگوریتم یادگیری ماشین مجموعه ای از دستورالعمل هاست که به کامپیوتر کمک می کند با تحلیل داده ها الگوها را یاد بگیرد و پیش بینی یا تصمیم گیری کند.
چهار نوع اصلی وجود دارد: یادگیری نظارت شده، بدون نظارت، نیمهنظارت شده و یادگیری تقویتی.
رگرسیون خطی، K-Means، جنگل تصادفی، SVM و K-NN از پرکاربردترین الگوریتم ها هستند.
از بازاریابی و تحلیل رفتار مشتری گرفته تا پزشکی، مالی، امنیت سایبری و حتی رباتیک.
خیر، دقت آن ها بستگی به کیفیت داده ها و روش آموزش دارد و معمولاً نیاز به بهبود و بازآموزی دارند.











این پست دارای 2 نظر است
خیلی مقاله خوبی بود، به خوبی توضیح داده بودید که یادگیری ماشین چطور دادهها رو تحلیل میکنه و مدل پیشبینی میسازه.
ممنون از نظر شما! هدف ما هم همین بود که مفاهیم پایه و انواع الگوریتمها برای همه قابل فهم باشه.