
۱. مقدمه
با گسترش روز افزون استفاده از خدمات فناوری اطلاعات و همچنین فراگیر شدن ابزارهای دیجیتالی، هر فرد به واسطه حضور خود در فضای مجازی باعث تولید حجم زیادی از دادهها میشود. این دادهها میتواند در دو دسته بندی کلی قرار بگیرد، یک قسمت اطلاعاتی است که انسان آن را تولید کرده و قسمت بعدی اطلاعاتی است که توسط ماشینهای مختلف (همانند مسیریابها، دوربینهای مدار بسته، حسگرهای مختلف و …) در حال تولید است. جهت اطلاعات بیشتر با نظم آران همراه باشید.

۱-۱-۱- تعریف دادههای عظیم (Big data)
اگر بخواهیم معادلی فارسی برای ‘ Big Data ‘ در نظر بگیریم میتوان به ‘ داده های عظیم ‘، ‘ کلان داده ‘ یا ‘ حجیم داده ‘ اشاره نمود که در مفهوم هیچ اختلافی با یکدیگر ندارند. کلان داده به حجم عظیمی از دادهها اطلاق میشود که پردازش آنها به وسیله پایگاه دادههای سنتی و ابزارهای آن غیرقابل انجام بوده و شامل انواع مختلفی از دادههای چند رسانهای، متن و … میشود که به شکل غیرقابل تصوری حجم آن در حال افزایش است. البته تشخیص وجه تمایز یک مجموعه اطلاعاتی که آن را کلان داده نامگذاری میکنیم و یک سیستم اطلاعاتی حجیم که ظاهراً شرایط آن را دارد بسیار مهم است. برای مثال یک سامانه دادهای که تمامی اطلاعات مردم ایران را در خود ذخیره میکند (نام، نام خانوادگی، شماره ملی و …) نمیتواند کلان داده بهشمار آید در صورتی که ظاهراً حجم بالایی از اطلاعات را در دل خود دارد. در بیشتر منابع و مقالات برای کلان داده سه ویژگی بیان شده است: حجم، گوناگونی و سرعت که اصطلاحاً به آن 3Vs نیز میگویند. البته در منابعی دیگر علاوه بر سه ویژگی اصلی گفته شده مقدار داده و پیچیدگی داده را نیز به ویژگیهای آن اضافه کردهاند. اما واضح است در صورتی که یک محیط جریان اطلاعاتی یا یک شبکه بتواند هر سه مورد نام برده شده را احراز کند به آن مجموعه کلان داده گفته میشود.
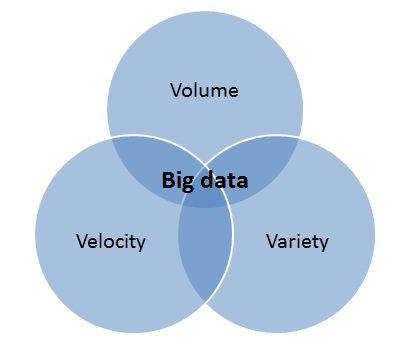
الف) حجم داده
شاید مهمترین ویژگی کلان داده را بتوان حجم عظیم داده بر شمرد، امروزه شرکتهای صاحب نام در عرصه فناوری اطلاعات خصوصا شبکههای اجتماعی به تنهایی میتوانند روزانه ۵۰۰ ترابایت اطلاعات جدید تولید کنند، به عنوان مثال سرویس اشتراک ویدئوی گوگل در هر دقیقه بیش از ۱۰۰ ساعت ویدئو بارگذاری شده توسط کاربران خود را دریافت و مدیریت میکند.
ب) گوناگونی داده
اطلاعات مربوط به حسگرهای مختلف، تلفنهای هوشمند، ارتباطات در شبکههای اجتماعی، دارای تنوع بالایی بوده و اطلاعاتی که به صورت ساختاری و بدون ساختار ذخیره میشوند از نظر گوناگونی بسیار پیچیده هستند، زیرا تمام این اطلاعات در پایگاه دادههای رابطهای سنتی ذخیره نشده است. علاوه بر این دادهها خام، نیمه ساختاری و یا کاملاً بدون ساختار است. به عنوان مثال ایمیلهای ارسالی و دریافتی، اطلاعات شبکههای اجتماعی و … همگی از نمونههای اطلاعات بدون ساختار است زیرا هیچ قالب از پیش تعیین شدهای برای ورود اطلاعات ندارند .
ج) سرعت داده
سرعت داده به این معنی است که دادهها از طریق منابع اطلاعاتی مختلف با سرعت بسیار بالایی تولید و منتقل میشوند، برای مثال سرعت تولید داده توسط حسگرهای RFID در یک مجموعه بسیار بالا بوده که علاوه بر ذخیره سازی این اطلاعات در لحظه، باید اطلاعات مورد تجزیه و تحلیل نیز قرار بگیرند. واضح است سیستمهای سنتی ذخیره سازی و تحلیل اطلاعات به سادگی نمیتوانند این جریان از اطلاعات را به صورت بلادرنگ مورد بررسی و نمایش قرار دهند.
۱-۱-۲- منشا دادههای عظیم
تا سال ۲۰۰۳ میلادی ۵ اگزا بایت (معادل ۵ میلیارد گیگابایت) اطلاعات توسط انسان تولید شده بود. اما امروزه این حجم از داده تنها در دو روز توسط انسان تولید میشود. شرکت IBM در گزارش خود اعلام کرد هر روز ۲.۵ اگزا بایت اطلاعات به دادههای دنیا افزوده میشود و ۹۰ درصد مقدار اطلاعاتی که در حال حاضر در دست داریم فقط در دو سال گذشته تولید شده است. (۲۰۱۲,singh) ابزار و فناوریهای مختلفی که در دسترس انسان امروزی قرار دارد، از دوربین و میکروفون و تلسکوپ و گوشی تلفن گرفته تا شبکههای بیسیم و ماهوارهای همگی در حال تولید اطلاعات و افزایش حجم دادههای عظیم هستند. برآوردها نشان میدهد هم اکنون ۴.۶ میلیارد گوشی موبایل در سراسر جهان وجود دارد و حدود ۱ تا ۲ میلیارد نفر هم به اینترنت دسترسی دارند. تعداد افرادی که امروزه با دادهها و اطلاعات سر و کار دارند به مراتب بیشتر از گذشته است. تعدادی از مواردی که به عنوان منشا دادههای عظیم میتوان از آنها نام برد عبارت است از:
• شبکه و رسانههای اجتماعی
• اینترنت اشیا
• کاربردهای ICT در بخشهای مختلف
• توسعه دسترسی نسلهای جدید به موبایل
• توسعه خدمات نوین بانکی
۱-۱-۳- اهمیت و کاربرد کلان داده
دولت آمریکا اعلام نمود تا سال ۲۰۱۲ بر روی زمینههای کاربردی کلان داده در حوزه سلامت، امنیت فضای مجازی، نظامی و دفاعی، انرژی و فعالیتهای تحقیقاتی مرتبط بیش از ۲۰۰ میلیون دلار هزینه نموده و نتایج آن را در جهت بهبود تصمیم گیری و سیاستگذاری در زمینههای نام برده شده به کار گرفته است. در واقع هدف اصلی سرمایه گذاران و سازمانها در زمینه کلان داده و کاربردهای آن تصمیم گیری دقیق و صحیح از طریق تحلیل حجم بیشتر دادهها است. روشهای تجزیه تحلیل کلان داده زمانی قدرت خود را نسبت به الگوریتمهای داده کاوی و یا سیستمهای پرس و جوی پیشرفته در پایگاه دادههای رابطهای سنتی نمایان میسازد که مجموعهای از دادههای ساختاری، نیمه ساختاری و بدون ساختار از منابع مختلف اطلاعاتی وارد سیستم شود. در ادامه با چند مورد از کاربردهای کلان داده در کسب و کار، اقتصاد و … بیشتر آشنا میشویم.
الف ) فناوری اطلاعات
از مهمترین موقعیتهای کاربردی کلان داده در عرصه فناوری اطلاعات میتوان به تجزیه و تحلیل وقایع شبکه در جهت کشف خطا و یا کشف نفوذ به شبکه اشاره نمود.
ب) اقتصاد و کسب و کار
شاید با ارزشترین کاربرد تحلیل کلان داده از نظر اقتصادی در حوزه کسب و کار باشد، در جایی که با حجم عظیمی از اطلاعات مشتریان و تراکنشهای خرید آنها مواجه هستیم. در ادامه برخی کسب و کارهایی که میتوانند مولد دادههای عظیم باشند و از تحلیل آنها متاثر شوند نام برده میشوند.
بازاریابی و فروش
با تجزیه و تحلیل مناسب دادههای مشتریان میتوان سیاستها و راهکارهای مناسب جهت افزایش فروش و بازاریابی دقیق را به کار برد. برای مثال میتوان با تجزیه و تحلیل اطلاعات مربوط به سبد خرید مشتریان، تنظیم قیمت صحیح محصول در جهت فروش بیشتر، طراحی محل قرارگیری محصولات در فروشگاه با توجه به اطلاعات آماری حرکت خریداران، کشف راهکارهای ترغیب مشتری در خرید مجدد از فروشگاه، مدیریت زنجیره عرضه تقسیم بندی مشتریان، پیشنهاد دقیق کالا در زمان مناسب به مشتری و . . . اشاره نمود.
اقتصاد و بانکداری
در زمینه اقتصاد و فعالیتهای بانکی نیز میتوان با آنالیز دادهها، میزان ریسک مرتبط با یک طرح را پیش بینی نمود و یا سوء استفاده از کارتهای اعتباری مشتریان را با تشخیص الگوی شک بر انگیز در استفاده از کارت اعتباری مشخص نمود. کشف نفوذ و یا تقلب، کلاهبرداری و یا پولشویی، با استفاده از تجزیه و تحلیل تراکنشهای مالی مشتریان با دیگر منابع اطلاعاتی نیز، امروزه بسیار کاربردی شده است.
تجارت اجتماعی
یکی از بسترهای مولد دادههای عظیم تجارت اجتماعی است. در تجارت اجتماعی، فعالیتهای تجاری و غیرتجاری در اجتماعات و بازارهای online صورت میگیرد. تجارت اجتماعی بستری است شامل فعالیتهای خرید و فروش و تعاملات وابسته به آن، که منجر به در نظر گرفتن همزمان مشتریان و فروشندگان میشود. این نوع از تجارت از فرآیند تصمیم گیری مشتری و رفتار خرید وی حمایت میکند.
ج) زندگی و سلامت
از کاربردهای تحلیل کلان داده در زمینه بیمه و سلامت میتوان به بالا بردن کیفیت نگهداری از بیماران و بهبود برنامه نگهداری آنان اشاره نمود. تعیین نوع رفتار با بیماران و پیشگویی میزان موفقیت اعمال جراحی، تعیین میزان موفقیت روشهای درمانی در برخورد با بیماریهای سخت، تشخیص بیماریها براساس انواع اطلاعات (تصاویر پزشکی، مشخصات بیمار احتمالی)، تأثیر داروها بر روند بهبودی بیماران و بررسی الگوهای مختلف ایجادکننده امراض در افراد و …از جمله مواردی است که توسط دادههای عظیم محقق میگردد.
د) شبکههای اجتماعی
یکی از کاربردیترین زمینههای کلان داده و تحلیل آن در شبکههای اجتماعی نمایان میشود. شبکههای اجتماعی چندی است که به صورت فراگیر در بین عموم جامعه، از فضاهای خصوصی گرفته تا بخشهای عمومی اجتماع، رسوخ کردهاند. شبکههای اجتماعی بسیار به روز و در تعامل با بدنه اصلی جامعه هستند. کانال توزیعی که به هیچ عنوان در دنیای قبل از این رسانهها وجود نداشت.

بررسی نظرات افراد در مورد یک محصول و بهینه سازی آن در جهت رسیدن به فروش بالاتر، بهینه سازی کالای پیشنهادی در موتورهای جستجو با توجه به لیست علاقه مندیهای فرد در شبکه اجتماعی وی، پیش بینی برنده انتخابات با استفاده از تجزیه و تحلیل نظرات کاربران در شبکههای اجتماعی از مهمترین کاربردهای کلان داده در شبکههای اجتماعی است. حال که این شبکه توزیع رایگان در اختیار شرکتها قرار گرفته است، صاحبین این جوامع مجازی در راستای بهرهوری هرچه بیشتر از این رسانهها در جهت تامین منافعشان تلاش میکنند. پیش از این همیشه صحبت از لو رفتن اطلاعات خصوصی اشخاص در فضاهایی مانند فیس بوک بوده است. ولی با تحولات کلان داده بسیار میتوان پا را فراتر گذاشت و به اطلاعات جمعی اشخاص و جوامع که خودشان نیز دسترسی ندارند، رسید. به عبارتی علاوه بر رد و بدل شدن اطلاعات، بخشی از هویت جوامع نیز در حال شکل گرفتن است و این فرهنگ را میتوان به تمامی بخشهای اجتماع تسری داد. فیس بوک اعلام کرده است برای هر کاربر به صورت متوسط در هر روز ۱۵۰۰ مطلب جدید از دوستان و مطالب مورد علاقه، برای مشاهده دارد. ولی اکثر کاربران وقت کافی برای مرور این همه مطلب ندارند. لذا با هوشمندی فیس بوک وارد کار میشود. با فیلتر کردن مطالب دلخواه افراد و نشان دادن مطالبی که میخواهد از بین مطالب جدید هر شخص، میتواند به عنوان شبکهای برای جهت دهی افکار و تبلیغات هوشمند عمل کند. کلان داده این امکان را فراهم ساخته است که فیس بوک علایق اشخاص را با توجه به مطالبی که به عنوان دلخواه انتخاب میکنند و مطالبی که منتشر میکنند، استخراج کند. در نتیجه دریایی از اطلاعات مفید برای یافتن مشتریان هدف شرکتها در دسترس دارد. پس از ایجاد جریانهای درآمد زایی جدید، کلان داده مسیر جدیدی نیز به اجبار پیش روی این شبکهها قرار داده است. این شبکهها جریانهای فوق العاده درآمد زایی را با استفاده از کلان داده ایجاد کردهاند، حال آن که روشهای بسیار بهتری برای به دست آوردن این اطلاعات پیدا شده است و آن اپلیکیشنهای پیامی مانند واتس آپ هستند. در حقیقت جریان درآمدزایی اصلی این شبکهها تبلیغات و رسانه بودن آنها است. از این رو با این محوریت تکنولوژی ابعاد جدیدی از خود را نمایان ساخته است.

۱-۱-۴- ابزارها و روشهای موجود
در گذشته اگر سازمانها با حجم عظیمی از دادهها بر روی پایگاه داده رابطهای خود مواجه میگشتند، به منظور نگهداری و تحلیل اطلاعات مجبور بودند از یک ابر رایانه و یا انباره دادهای استفاده کند. ضعف پایگاه دادههای رابطهای در نگهداری و تجزیه و تحلیل حجم عظیمی از دادههای نیمه ساختاری و بدون ساختار نمایان گشت و دانشمندان با مطرح کردن فناوری جدیدی به نام No SQL اقدام به ساخت نسل جدیدی از پایگاههای دادهای که میتواند حجم عظیمی از اطلاعات را نگهداری و پردازش کند، نمودند. زمینههایی که این پایگاههای دادهای مناسب آنها هستند و از خود شایستگی بیشتری در آنها نشان میدهند، به ترتیب در ادامه آورده شدهاند:
• دادههای با توالی نوشتن بالا و توالی خواندن کم: همانند شمارندههای بازدید صفحات وب، دستگاههای وقایعنگار یا تلسکوپهای فضایی.
• دادههای با توالی خواندن بالا و توالی نوشتن بسیارکم: همانند دادههای گذرا و کش شدهای از تصاویر، اسناد کاربردهای نیازمند دسترس پذیری بالا و با توقف خدمات بسیار کم
• دادههایی که باید در نقاط مختلف جغرافیایی با هم همگامسازی شوند: مانند دادههایی که در کلاسترهای مختلف یک شبکه بزرگ سازمانی با دفاتر مختلف پراکنده در سطح جغرافیایی وسیع موجودند و نیاز است تا همواره و با بالاترین سرعت و کمترین هزینه ممکن با هم همگام سازی شوند.
• دادههای بزرگ تجاری یا مرتبط با تحلیل وب که شمای خاصی ندارند: چنین دادههایی تقریباً شکل و قالب از پیش تعیین شدهای ندارند و براساس محتوای متغیر موجود روی وب تولید میشوند و در بیشتر موارد به فعالیت کاربران و سیستمهای نرمافزاری مرتبط وابسته هستند.
اولین و مهم ترین مزایای پایگاههای داده NoSQL عدم طراحی شمای (الگو) خاص برای دادهها است. در این سیستم دادههای ورودی میتواند هر موقع تغییر نوع پیدا کرده و سیستم باید خودش را با آن مطابق کند. دومین مزیت قابلیت چند بخشی شدن خودکار و تشخیص هوشمند یکپارچگی است. در مدلهای سنتی، SQL، طراح باید چند سرور بودن را در طراحی خود حتما لحاظ میکرد و بر طبق آن شمای پایگاه داده را پیاده سازی میکرد ولی در سیستم NoSQL چند سرور بودن بخاطر هوشمندی و بالا بودن سطح سیستم هیچ مانعی برای ادامه کار ندارد. سومین مزیت وجود Cache برای افزایش سرعت بازیابی اطلاعات میباشد که همانند پردازنده در مواجه شدن با منابع مشابه و یکسان که آنها را در Cache نگهداری میکرد در سیستم NoSQL هم دادههای پر استفاده در Cache نگهداری میشوند. پس استفاده از NoSQL باعث افزایش سرعت در طراحی و اجرای پایگاه داده شده و همچنین محدودیتهای قالب قدیمی را از میان بر میدارد که بیشتر مورد نیاز دنیای امروز و آینده اطلاعات و دادهها میباشد.

۱-۱-۵- مسائل حوزه تحلیل اطلاعات در کلان داده
الف ) عدم کاربرد روشهای سنتی تحلیل اطلاعات در کلان داده
در علم تجزیه و تحلیل سنتی دادهها (داده کاوی)، دادههای اولیه به طور معمول در انبارههای دادهای قرار گرفته و هر انباره دادهای نیز میبایست از یک قالب از پیش تعریف شده برای نگهداری و مدیریت دادههای خود استفاده میکرد تا بتواند براساس نیاز و کاربرد، تجزیه و تحلیل خود را بر روی اطلاعات اجرایی نماید. استفاده از انباره دادهای در تحلیل اطلاعات معایبی را با توجه به کاربردهای امروز فناوری در تصمیم گیری دارد. مشکل اول این است دادههای آن به روز نبوده و از عمر تولید آن مدت زمان زیادی میگذرد و در بعضی از کاربردهای تحلیل کلان داده نیاز به دادههای جدید و بر خط وجود دارد. مشکل دوم مربوط به مدیریت اطلاعات در انباره دادهای است که به شکل متمرکز بوده و توسط یک تیم مدیریت و کنترل میشود اما در کلان داده، حجم عظیمی از دادهها به شکل غیرمتمرکز و توزیع شده قرار دارد که هر عمل پردازشی و تحلیلی روی این حجم از داده باید قابلیت اجرای موازی بر روی تعداد زیادی خوشهها در شبکه را داشته باشد.

ب ) چالشهای تحلیل داده
در این حوزه همواره چالشهای زیادی به دلیل ماهیت کلان داده و ویژگیهای آن مطرح بوده و هست. از چالشهای روز آن میتوان به تحلیل اطلاعات نیمه ساختاری و بدون ساختار اشاره نمود. یکی از روشهای تحلیل اطلاعات در دادههای بدون ساختار متنی استفاده از ‘فرا داده’ است برای مثال فردی در شبکه اجتماعی پیامی به این شکل مینویسد من از وضعیت پوشش شبکه تلفن همراه خود راضی نیستم در صورتی که در تبلیغات گفته شده بود بهترین پوشش شبکه را دارد، بهتر است سرویس دهنده خود را عوض کنم! ‘ برای آگاه شدن از قصد مشتری شبکههای اجتماعی با استفاده از موتور استنتاج خود فرا دادههای کلیدی مانند’ سرویس دهنده’ , ‘راضی نیستم ‘,’ رضایت’ , ‘قصد’ را نشانه گذاری کرده و در لحظه میتوانند دادهها را تحلیل کنند. مشخص است که کلان داده محدود به متن نبوده و شامل حجم عظیمی از تصاویر، صداها و ویدئو نیز میباشد و همواره مبحث مدیریت فرا دادهها به عنوان یکی از روشهای تحلیل اطلاعات در کلان داده موضوعی جذاب است که نیاز به پژوهش بیشتری دارد.
ج) چالشهای امنیت و حریم شخصی
از چالشهای حریم خصوصی در کلان داده خصوصا در شبکههای اجتماعی، اطلاعات حساس افراد است که پس از تحلیل ممکن است به کشف دانشی منجر شود که برای فرد خصوصی بوده و تمایل ندارد دارنده اطلاعات و یا هر شخص دیگری از آن اطلاع داشته باشد. همچنین مجری قانون و یا دولت ممکن است از اطلاعات حریم خصوصی افراد استفاده کنند. همچنین اطلاعات شخصی افراد در تبلیغات مؤثر موتورهای جستجو، شبکههای اجتماعی، پست الکترونیکی و … است مورد بهره برداری قرار گیرد.
د) چالشهای فنی و پردازشی
بعضی از الگوریتمها و فناوریهای تحلیل دادهها در مقیاس پایین عملکرد مناسبی را از خود نشان دادهاند اما گفته میشود بعضی از الگوریتمها و فناوریهای حال حاضر که در ادامه آمده است مقیاسپذیری به اندازه حجم زتابایت را ندارند: تکیکهای یادگیری ماشین، تحلیل اطلاعات متنی- ویدئویی- صوتی بدون ساختار -تصویرسازی دادهها – رایانش ابری – داده کاوی – الگوریتمهای گراف و مش – اضافه شدن دادههای ساختاری به الگوریتمهای موجود.
تکنولوژی دادههای عظیم چیست؟
دادههای عظیم تنها پیام آور فرصتها نیستند، بلکه چالشهای تکنیکی خود را به همراه دارد. سیستمهای پردازشی سنتی قادر به انجام پردازش روی دادههای حجیم نبوده و ما نیاز به نسل جدیدی از تکنولوژی اطلاعات برای پردازش دادههای عظیم خواهیم داشت. تکنولوژیهای دادههای عظیم به پنج گروه اصلی تقسیم بندی میشوند که در جدول زیر نمایش داده میشود: برای آشنایی اجمالی با هر کدام از این پنج گروه، در صفحات بعد شرح مختصری از هر کدام و برخی از تکنولوژیهای مورد استفاده از آنها آمده است.
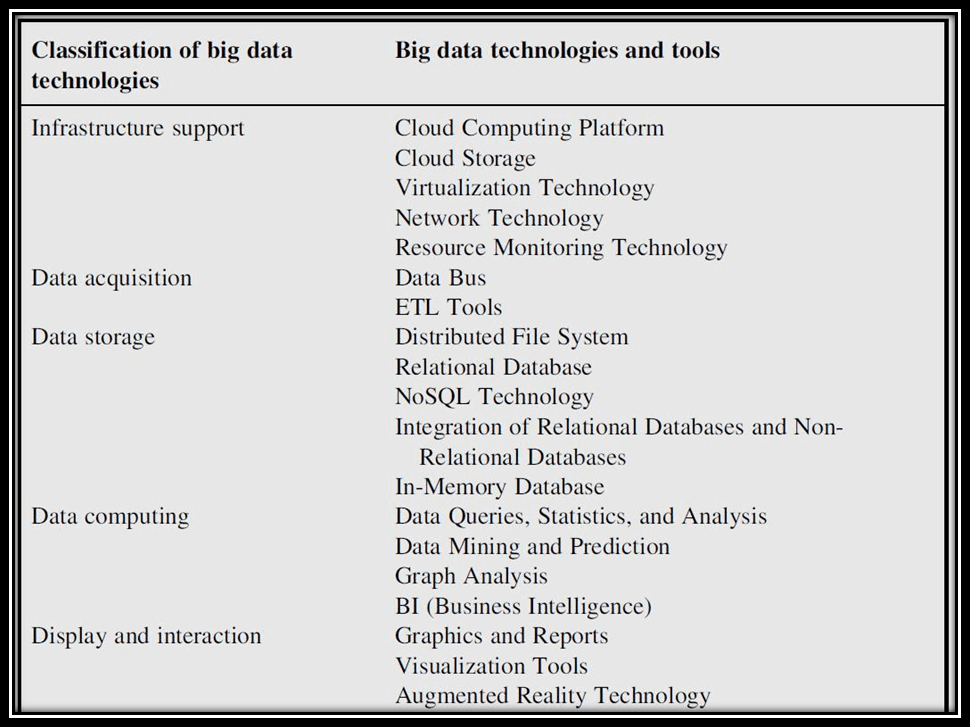
۱- زیر ساخت (Infrastructure support)
به طور کلی شامل سطوح زیر ساختی داده در حوزههای مدیریت مرکز داده، پلتفرمهای پردازش ابری، تجهیزات و تکنولوژیهای ذخیره سازی ابری، تکنولوژیهای شبکهها و تکنولوژیهای مانیتورینگ منابع میباشد.
پردازش دادههای عظیم نیاز به پشتیبانی از دادههای مبنتی بر ابر و منابع فیزیکی در ابعاد بالا دارد.
برخی از تکنولوژیهای مطرح در پردازش ابری عبارتند از :
Amazon Web Services (AWS)
Google’s App Engine
Microsoft’s Windows Azure Services
در کنار این تکنولوژیهای تجاری، تعداد زیادی از پلتفرمهای متن باز پردازش ابری وجود دارد.
Open Nebula -Eucalyptus -Nimbus -Open Stack
۲- جمع آوری دادهها (Data acquisition)
جمع آوری دادهها پیشنیاز پردازش اطلاعات است. ابتدا باید اطلاعات را جمع آوری کنیم که بتوانیم لایههای پردازش اطلاعات را روی آنها مستقر نمائیم.
با وجود نرم افزارها، سخت افزارها و سنسورهای مختلف، برای جمع آوری اطلاعات باید فرآیند ETL رو دادههای انجام شود. که بتواند اطلاعات مختلف تولید شده را تمیز، فیلتر، تبدیل و چک نماید تا اطلاعات صحیح داشته باشیم.
در واقع برای پشتیبانی از چندین منبع مختلف و متنوع باید عملیات جمع آوری به درستی انجام شود.
ابزارهای ETL در دادههای عظیم با ابزارهای سنتی تفاوت دارد، از یک سو حجم دادهها و از سوی دیگر سرعت تولید داده در دادههای عظیم که بسیار سریع است.
در حقیقت برای تجیمع و جمع آوری دادههای مختلف از نرم افزارها، دوربینها، سنسورها، گوشیهای موبایل، دستگاههای GPS و ….. باید از یک گذرگاه جامع استفاده نماییم که بتواند جامعیت را برقرار سازد که به Enterprise data bus معروف است.
EDS یک لایه مجازی برای ورود دادهها ایجاد میکند.
۳- ذخیره سازی دادهها (Data storage)
بعد از جمع آوری و تبدیل دادهها باید دادهها ذخیره و آرشیو شود. در مواجهه با اطلاعات عظیم تکنولوژیهای فایلها و بانکهای اطلاعاتی توزیع شده مورد استفاده قرار میگیرد.
سیستمهای فایل توزیع شده برای ذخیره سازی دادههای عظیم از Nodeهای مختلف برای نگهداری فایلهای مختلف استفاده میکند و بانکهای اطلاعاتی NoSQL برای پردازش و تحلیل حجم بالایی از دادههای غیرساخت یافته استفاده میکند.
برخی از تکنولوژیهای فایلهای توزیع شده عبارتند از:
(Open Source Solution)
Hadoop Distributed File System(HDFS) and MapReduce
Google File System (GFS)
و در بانکهای اطلاعاتی:
HBase -Google BigTable-Facebook’s Cassandra.-MongoDb و…
۴- محاسبات دادهای (Data computing)
پرس و جو روی دادهها، آمار، آنالیز، پیش بینی، کاوش، تحلیل نموداری، هوش کسب و کار در زیر مجموعه محاسبات دادهای قرار میگیرند.
محاسبات بر روی دادههای عظیم با تکنولوژیهای متنوعی انجام میشود که در سه گروه دسته بندی میشوند:
۴-۱: پردازش افلاین (Offline batch computing)
که شامل تکنولوژیهای و ابزارهای مختلفی میباشد که برخی از آنها عبارتند از:
Hadoop platform –Hbase – Hive- Zookeeper – Avro – Pig-Spark
و…
که به نحوه استقرار و جایگاه آنها در مجموع اکو سیستم هادوب میگویند.
تصویر زیر نمونهای از این اکو سیستم است:
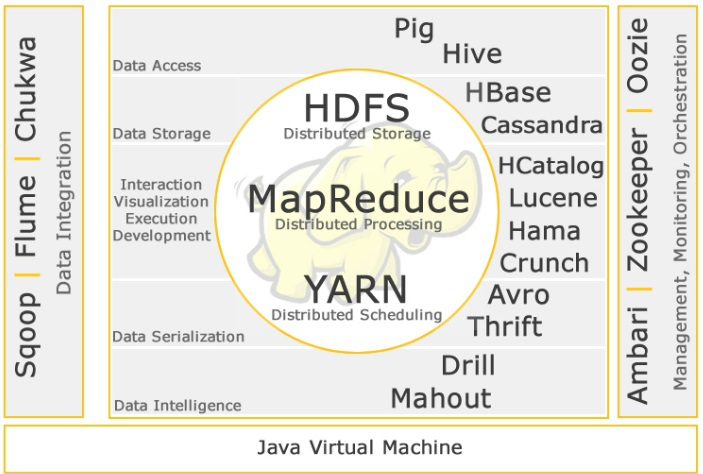
۴-۲: Real-time interactive computing
یکی از نکات قوت دادههای عظیم است که بتواند به صورت برخط محاسبات را در حجم بالا و سرعت بالا انجام دهد.
برخی از تکنولوژیهای معروف آن عبارتند از:
Facebook’s open-source Scribe -LinkedIn’s open-sourceKafka
Cloudera’s open-source Flume -Taobao’s open-source TimeTunnel
Hadoop’s Chukwa –Spark-Google BigQuery, Dremel
۴-۳: Streaming computing
پردازش جریانی (Streaming Computing) یا پردازش پیوسته، یک فناوری قدرتمند در عصر اطلاعات است که در آن دادهها در زمان واقعی و به صورت پیوسته تحلیل و پردازش میشوند. در محیط متلب، امکانات قدرتمندی برای پردازش جریانی وجود دارد که به کمک آنها میتوان عملیات پیچیده را به صورت همزمان و در حالت زمان واقعی انجام داد. این امکان به مدیران و محققان کمک میکند تا به صورت سریع و دقیق ترجمههای نوین را در زمینههای مختلف از جمله پزشکی، مهندسی، تحلیل مالی و غیره انجام دهند.
بدیهی است برای شروع هر پروزه در این حوزه باید در فاز مطالعاتی تکنولوژیهای مورد نیاز بدرستی شناسایی شود.
مطالب بیشتر: سیستمهای یکپارچه شرکتهای مترو











این پست دارای 4 نظر است
مطلبتون درباره کلانداده خیلی کامل و مفصل بود، اما یک سؤال مهم برام پیش اومد؛ با توجه به اینکه حجم و سرعت تولید دادهها اینقدر بالاست، چطور میشه در عمل دادههای بدون ساختار مثل متن و تصویر رو سریع و دقیق تحلیل کرد؟ آیا روشهای فعلی یادگیری ماشین واقعاً جوابگوی این سطح از حجم داده هستند؟
سؤال خیلی خوبی مطرح کردید. در حال حاضر تحلیل دادههای بدون ساختار معمولاً با ترکیب چند تکنیک انجام میشه؛ مثل یادگیری عمیق برای پردازش متن، تصویر و ویدئو، و استفاده از سیستمهای توزیعشده مثل Hadoop و Spark برای مقیاسپذیری. الگوریتمهای فعلی یادگیری ماشین هنوز چالشهایی در مقیاسهای بسیار بزرگ دارند، اما با پیشرفت GPUها، رایانش ابری و مدلهای پیشآموزشدیده (Pre-trained Models)، دقت تحلیلها به شکل قابل توجهی بالا رفته. به همین دلیل امروزه ترکیب زیرساخت توزیعشده + مدلهای هوش مصنوعی بهترین راهکار برای مدیریت کلانداده محسوب میشه.
هوش تجاری دقیقا چه تفاوتی با گزارش گیری معمولی داره؟
گزارش گیری فقط نمایش دادههای گذشته است، اما هوش تجاری با تحلیل، مقایسه و پیش بینی دادهها به مدیران کمک میکند تصمیمات آینده را آگاهانه و بر اساس واقعیت بگیرند.