
1. Introduction
With the increasing use of information technology services and the spread of digital tools, every person generates a large amount of data due to their presence in the virtual space. This data can be divided into two general categories, one part is information that is produced by humans and the next part is information that is being produced by different machines (such as routers, CCTV cameras, various sensors, etc.).

1-1-1- Big data definition
If we want to consider a Persian equivalent for ‘Big Data’, we can refer to ‘big data’, ‘big data’ or ‘bulky data’, which have no difference in concept. Big data refers to a huge amount of data that cannot be processed by traditional databases and its tools, and includes various types of multimedia data, text, etc., which is increasing in an unimaginable way. Of course, it is very important to distinguish between an information set that we call big data and a massive information system that apparently has its conditions. For example, a data system that stores all the information of Iranian people (name, surname, national number, etc.) cannot be considered big data if it apparently contains a large amount of information. In most sources and articles for big data, three characteristics are stated: Volume, variety and speed, which are also called the 3 Vs. Of course, in other sources, in addition to the mentioned three main features, data amount and data complexity have also been added to its features. But it is clear that if an information flow environment or a network can verify all three mentioned items, it is called a big data set.
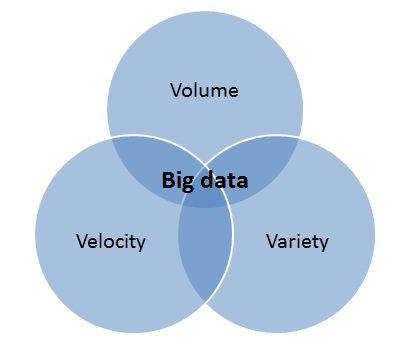
A) Data volume
Perhaps the most important feature of big data can be considered as a huge amount of data, today, well-known companies in the field of information technology, especially social networks, alone can produce 500 terabytes of new information every day, for example, Google’s video subscription service has more than 100 hours of video uploaded by its users every minute. receives and manages
b) Data diversity
Information related to various sensors, smart phones, communication in social networks, has a high variety, and the information that is stored in structured and unstructured form is very complex in terms of variety, because all this information is not stored in traditional relational databases. In addition, the data is raw, semi-structured or completely unstructured. For example, sent and received e-mails, information on social networks, etc. are all examples of unstructured information because they have no predetermined format for entering information.
c) Data speed
Data speed means that data is generated and transmitted through different information sources at a very high speed, for example, the speed of data generation by RFID sensors in a set is very high, which in addition to storing this information in real time, the analyzed information must be and analysis are also included. It is clear that traditional information storage and analysis systems simply cannot analyze and display this flow of information in real time.
1-1-2- The origin of huge data
By 2003, 5 exabytes (equivalent to 5 billion gigabytes) of information had been produced by humans. But today, this volume of data is produced by humans in only two days. IBM announced in its report that 2.5 exabytes of information are added to the world’s data every day, and 90% of the amount of information we currently have was produced only in the last two years. (2012, Singh) Various tools and technologies that are available to humans today, from cameras and microphones and telescopes and telephones to wireless and satellite networks, are all producing information and increasing the volume of huge data. Estimates show that there are currently 4.6 billion mobile phones worldwide, and about 1-2 billion people have access to the Internet. The number of people who deal with data and information today is far more than in the past. Some of the things that can be mentioned as sources of huge data are:
• Network and social media
• Internet of Things
• ICT applications in different sectors
• Development of mobile access for new generations
• Development of new banking services
1-1-3- The importance and use of big data
The US government announced that until 2012, it will spend more than 200 million dollars on the fields of big data applications in the fields of health, cyber security, military and defense, energy and related research activities, and the results will be used to improve decision-making and policy-making in the fields of The mentioned name is used. In fact, the main goal of investors and organizations in the field of big data and its applications is to make accurate and correct decisions through the analysis of large volumes of data. Big data analysis methods show their power compared to data mining algorithms or advanced query systems in traditional relational databases when a set of structured, semi-structured and unstructured data from different information sources is entered into the system. In the following, we will learn more about some of the applications of big data in business, economy, etc.
A) Information technology
One of the most important applications of big data in the field of information technology is the analysis of network events in order to detect errors or network intrusions.
b) Economy and business
Perhaps the most economically valuable application of big data analytics is in the business domain, where we are dealing with huge amounts of customer information and their purchase transactions. In the following, some businesses that can generate huge data and be affected by their analysis are mentioned.
Marketing and sales
With proper analysis of customer data, appropriate policies and strategies can be used to increase sales and accurate marketing. For example, by analyzing the information related to customers’ shopping carts, it is possible to adjust the correct price of the product in order to sell more, to design the placement of products in the store according to the statistical information of the buyers’ movements, to discover ways to persuade customers to buy again from the store, to manage the supply chain. Customer segmentation, accurate product offer at the right time to the customer and . . cited.
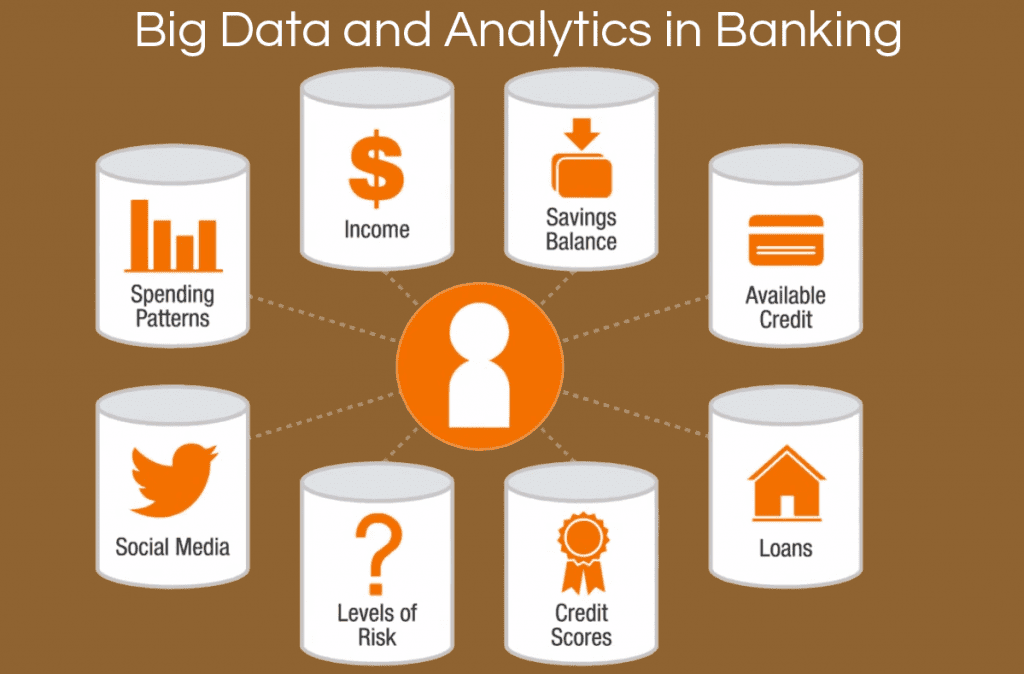
Economics and banking
In the field of economics and banking activities, it is also possible to predict the amount of risk associated with a project by analyzing data, or identify the misuse of customers’ credit cards by identifying suspicious patterns in the use of credit cards. Discovering intrusion or fraud, fraud, or money laundering, using the analysis of customers’ financial transactions with other information sources, has become very practical today.
Social business
One of the platforms that generate massive data is social commerce. In social commerce, commercial and non-commercial activities take place in communities and online markets. Social commerce is a platform that includes buying and selling activities and related interactions, which leads to simultaneous consideration of customers and sellers. This type of business supports the customer’s decision making process and buying behavior.
c) Life and health
Among the applications of big data analysis in the field of insurance and health, we can mention raising the quality of patient care and improving their care plan. Determining the type of behavior with patients and predicting the success rate of surgical operations, determining the success rate of treatment methods in dealing with difficult diseases, diagnosing diseases based on various types of information (medical images, possible patient characteristics), the effect of drugs on the recovery process of patients, and investigating different disease-causing patterns in People and … are among the things that are realized by huge data.
d) social networks
One of the most practical fields of big data and its analysis appears in social networks. For some time now, social networks have penetrated widely among the general public, from private spaces to public parts of society. Social networks are very up-to-date and interact with the main body of society. A distribution channel that did not exist in the world before these media.

Examining people’s opinions about a product and optimizing it in order to achieve higher sales, optimizing the recommended product in search engines according to the person’s list of interests in his social network, predicting the winner of the election by using the analysis of users’ opinions in Social networks are one of the most important applications of big data in social networks. Now that this free distribution network has been provided to the companies, the owners of these virtual communities are trying to maximize the productivity of these media in order to secure their interests. Before, there has always been talk of the disclosure of private information in places like Facebook. But with big data developments, it is possible to go further and reach the collective information of individuals and communities that they do not have access to. In other words, in addition to the exchange of information, a part of the society’s identity is also being formed, and this culture can be extended to all parts of society. Facebook has announced that each user has an average of 1,500 new posts from friends and favorites to view each day. But most of the users don’t have enough time to review all this information. Therefore, Facebook comes to work with intelligence. By filtering people’s favorite content and showing the content they want from among the new content of each person, it can act as a network for directing thoughts and intelligent advertising. Big data has made it possible for Facebook to mine people’s interests based on what they like and what they post. As a result, a sea of useful information is available for companies to find their target customers. After creating new revenue streams, big data has forced a new path for these networks. These networks have created tremendous revenue streams using big data, but there are much better ways to get this information and that is messaging apps like WhatsApp. In fact, the main revenue stream of these networks is their advertising and media. Therefore, with this focus, technology has revealed new dimensions.

1-1-4- Existing tools and methods
In the past, if organizations faced a huge amount of data on their relational database, they had to use a supercomputer or data warehouse in order to store and analyze the information. The weakness of relational databases in maintaining and analyzing a large amount of semi-structured and unstructured data was revealed, and scientists proposed a new technology called No SQL to build a new generation of databases that can store and process a large amount of information. they did The fields that these databases are suitable for and show more competence in are listed below:
• Data with high write sequence and low read sequence: such as web page view counters, chronographs or space telescopes.
• Data with high read sequence and very low write sequence: such as transient and cached data from images, document applications that require high availability and with very little service interruption.
• Data that must be synchronized in different geographical locations: such as data that are available in different clusters of a large organizational network with different offices scattered over a wide geographical area and need to be synchronized with each other at the highest speed and lowest possible cost. .
• Big business data or related to web analysis that do not have a specific format: such data have almost no predetermined shape and format and are generated based on the variable content available on the web and in most cases depend on the activity of users and related software systems.
The first and most important advantage of NoSQL databases is not to design a specific schema (pattern) for the data. In this system, the input data can be changed at any time and the system must adapt to it. The second advantage is the ability of automatic multipartitioning and intelligent integrity detection. In traditional models, SQL, the designer must have taken into account multi-server in his design and implemented the database structure accordingly, but in NoSQL system, multi-server is not an obstacle to continue work due to the intelligence and high level of the system. The third advantage of having a cache is to increase the speed of data recovery, as the processor encounters the same resources that it stored in the cache, in the NoSQL system, the frequently used data is also stored in the cache. So, the use of NoSQL increases the speed in the design and implementation of the database and also removes the limitations of the old format, which is most needed in today’s and future world of information and data.

1-1-5- Problems in the field of information analysis in big data
A) Non-use of traditional information analysis methods in big data
A) Non-use of traditional information analysis methods in big data The use of data warehouse in information analysis has disadvantages according to today’s technology applications in decision making. The first problem is that its data is not up-to-date and a long time has passed since its production life, and in some applications of big data analysis, there is a need for new and online data. The second problem is related to information management in a data warehouse that is centralized and managed and controlled by a team, but in big data, there is a huge amount of data in a decentralized and distributed form, and any processing and analysis on this amount of data Data must be able to run in parallel on a large number of clusters in the network.

b) Challenges of data analysis
In this field, there have always been many challenges due to the nature of big data and its characteristics. One of the challenges of the day can be mentioned the analysis of semi-structured and unstructured information. One of the methods of analyzing information in unstructured textual data is the use of “metadata”. For example, a person writes a message in a social network like this: I am not satisfied with the state of my mobile phone network coverage, if it was said in the advertisement that the best network coverage is available. Yes, I’d better change my server! In order to be aware of the customer’s intention, social networks use their inference engine to mark key meta-data such as ‘servicer’, ‘not satisfied’, ‘satisfaction’, ‘intention’ and analyze the data at the moment. It is clear that big data is not limited to text and includes a huge amount of images, sounds and video, and the subject of metadata management as one of the methods of information analysis in big data is always an attractive topic that needs more research.
c) Security and privacy challenges
One of the challenges of privacy in big data, especially in social networks, is the sensitive information of people, which after analysis may lead to the discovery of knowledge that is private for the person and does not want the owner of the information or any other person to know about it. Also, law enforcement or the government may use people’s privacy information. Also, people’s personal information can be used in effective advertisements of search engines, social networks, e-mail, etc.
d) technical and processing challenges
Some low-scale data analysis algorithms and technologies have shown good performance, but it is said that some of the current algorithms and technologies listed below do not have the scalability of zettabytes: Machine learning techniques, unstructured text-video-audio data analysis – data visualization – cloud computing – data mining – graph and mesh algorithms – addition of structured data to existing algorithms.
What is big data technology?
Big data is not only a messenger of opportunities, but also brings its own technical challenges. Traditional processing systems are not able to process large data and we will need a new generation of information technology to process large data. Big data technologies are divided into five main groups, as shown in the table below: For a brief introduction to each of these five groups, on the following pages there is a brief description of each and some of the technologies used by them.
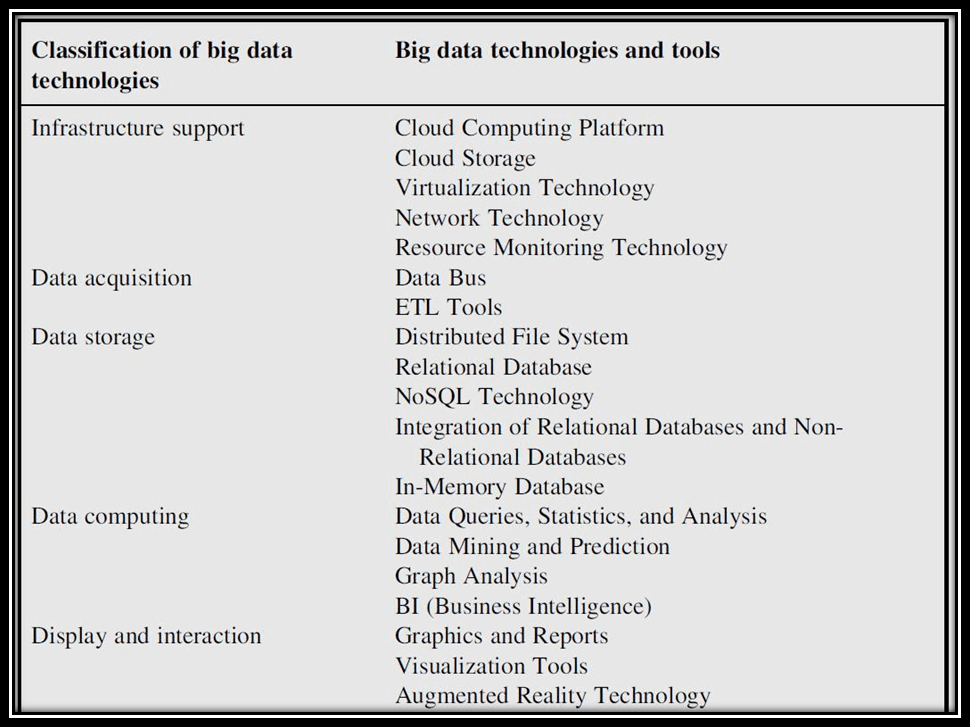
1- Infrastructure support
In general, it includes data infrastructure levels in the areas of data center management, cloud processing platforms, cloud storage equipment and technologies, network technologies and resource monitoring technologies.
Big data processing requires the support of cloud-based data and physical resources in high dimensions.
Some of the prominent technologies in cloud processing are:
Amazon Web Services (AWS)
Google’s App Engine
Microsoft’s Windows Azure Services
Alongside these commercial technologies, there are a large number of open source cloud computing platforms.
Open Nebula -Eucalyptus -Nimbus -Open Stack
2- Data acquisition
Data collection is a prerequisite for information processing. First, we need to collect information so that we can deploy information processing layers on them.
With different software, hardware and sensors, ETL process should be done on data to collect information. which can clean, filter, transform and check the various information produced so that we have correct information.
In fact, to support several different and diverse resources, the collection operation must be done correctly.
ETL tools in big data are different from traditional tools, on the one hand, the volume of data, and on the other hand, the speed of data generation in big data, which is very fast.
In fact, to aggregate and collect various data from software, cameras, sensors, mobile phones, GPS devices and… We must use a comprehensive bus that can establish comprehensiveness, which is known as Enterprise data bus.
EDS creates a virtual layer for data entry.
3- Data storage
After collecting and converting the data, the data must be stored and archived. In the face of huge information, technologies of files and distributed databases are used.
Distributed file systems use different nodes to store different files for storing huge data, and NoSQL databases use large volumes of unstructured data to process and analyze.
Some distributed file technologies include:
(Open Source Solution)
Hadoop Distributed File System (HDFS) and MapReduce
Google File System (GFS)
And in databases:
HBase -Google BigTable-Facebook’s Cassandra.-MongoDb و…
4- Data computing
Data query, statistics, analysis, forecasting, exploration, graph analysis, business intelligence are included under data computing.
Calculations on huge data are performed with various technologies, which are categorized into three groups:
4-1: Offline batch computing
which includes various technologies and tools, some of which are:
Hadoop platform –Hbase – Hive- Zookeeper – Avro – Pig-Spark
And…
which is called the manner of establishment and their place in the Hadob ecosystem.
The following image is an example of this ecosystem:
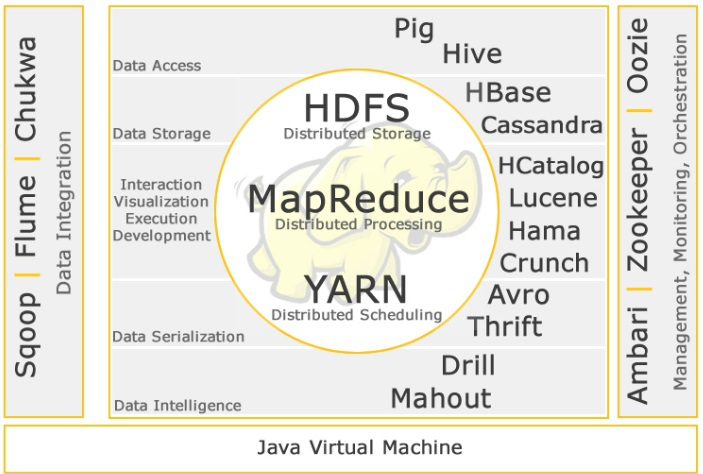
4-2: Real-time interactive computing
One of the strengths of huge data is that it can perform online calculations in high volume and high speed.
Some of its famous technologies are:
Facebook’s open-source Scribe – LinkedIn’s open-source Kafka
Cloudera’s open-source Flume -Taobao’s open-source TimeTunnel
Hadoop’s Chukwa –Spark-Google BigQuery, Dremel
4-3: Streaming computing
In this field, there have always been many challenges due to the nature of big data and its characteristics. One of the challenges of the day can be mentioned the analysis of semi-structured and unstructured information. One of the methods of analyzing information in unstructured textual data is the use of “metadata”. For example, a person writes a message in a social network like this: I am not satisfied with the state of my mobile phone network coverage, if it was said in the advertisement that the best network coverage is available. Yes, I’d better change my server! In order to be aware of the customer’s intention, social networks use their inference engine to mark key meta-data such as ‘servicer’, ‘not satisfied’, ‘satisfaction’, ‘intention’ and analyze the data at the moment. It is clear that big data is not limited to text and includes a huge amount of images, sounds and video, and the subject of metadata management as one of the methods of information analysis in big data is always an attractive topic that needs more research.
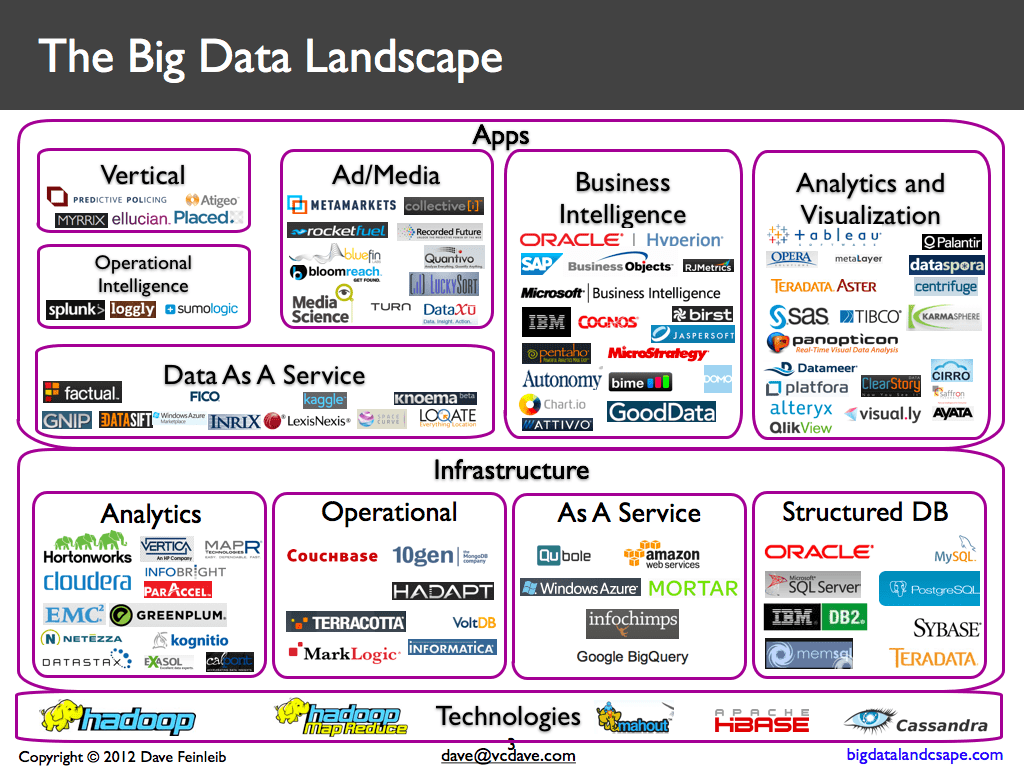
Obviously, to start any project in this field, the required technologies must be properly identified in the study phase.










