فرآیند کریسپ (CRISP) -روش شناسی کریسپ و چرخه کریسپ
نظم آران » فرآیند کریسپ (CRISP) -روش شناسی کریسپ و چرخه کریسپ
تعداد بازدید : 1061
چرخه CRISP را بشناسید – امروزه یادگیری ماشین (machine learning) به عنوان یکی از نیاز های اصلی صنعت بسیار مورد توجه مدیران و کاربران قرار گرفته است. برای اجرای موفق یادگیری ماشین (machine learning) باید مراحل و گام های آن به درستی طی شود. در این قسمت مراحل اجرای موفق یادگیری ماشین (machine learning) را به صورت چرخه CRISP تفسیر می شود جهت اطلاعات بیشتر با نظم آران همراه باشید.
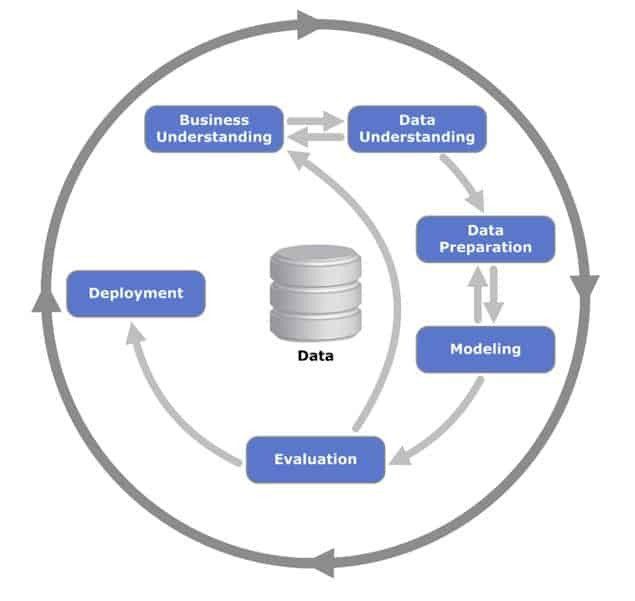
چرخه CRISP
۱- درک کسب و کار
۲- درک داده
۳- پیش پردازش و آماده سازی داده ها
۴- ایجاد مدل
۵- تست کردن و ارزیابی کردن و گرفتن فیدبک
۶- پیاده سازی و استقرار
۱- درک کسب و کار
درک کسب و کار نیازمند به مدیریت دانش جدید و مشخص کردن شفاف اهداف کسب و کار است. در این مرحله باید شرایط کسب و کار را بررسی کنیم و به تحلیل رقبا و رفتار مشتریان بپردازیم. و هم چنین تیم توسعه مسئول جمع آوری داده، تحلیل داده و داده کاوی هستند.
۲- درک دادها
فعالیت اصلی در فرآیند داده کاوی شناسایی داده های مرتبط از پایگاه های داده موجود است. و مشخص می کنیم داده را به چه صورتی ذخیره شوند. تحلیلگر برای درک بهتر دادهها، اغلب از انواع تکنیکهای آماری و گرافیکی استفاده میکند. داده ها را می توان به دو دسته کمی و کیفی طبقه بندی کرد. داده های کمی با استفاده از مقادیر عددی یا داده های عددی اندازه گیری می شوند. می تواند گسسته و عدد صحیح یا پیوسته باشد که می توان از میانگین، حداقل و حداکثر، میانه و انحراف معیار استفاده کرد. داده های کیفی که به عنوان داده های طبقه ای و به صورت داده های اسمی و ترتیبی هستند.
۳- پیش پردازش و آماده سازی داده ها
در مرحله آماده سازی و پیش پردازش داده، دادههای شناساییشده آماده تجزیه و تحلیل با روشهای داده کاوی می شوند. در CRISP پیش پردازش داده ها بیشترین زمان را نیاز دارد. زیرا در دنیای کسب و کار داده ها تمیز CLEAN نیستند و تا ۸۰ درصد زمان داده کاوی برای مرتب سازی و آماده سازی آن ها صرف می شود.
۴- ایجاد مدل
ایجاد مدل: ایجاد مدل شامل ارزیابی، تحلیل و مقایسه مدل های مختلف است. تکنیکهای مدلسازی متنوعی را می توان بر مجموعه داده پیش پردازش شده لحاظ کرد. بهترین مدل پیشنهادی وجود ندارد بلکه براساس ارزیابی و ازمایش مدل ها در جهت رسیدن به نتایج بهینه تعیین می شود.
۵- تست کردن و ارزیابی کردن و گرفتن فیدبک
– تست، ارزیابی و گرفتن بازخورد: در این مرحله مدل های توسعه یافته از نظر صحت و کلی بودن ارزیابی می شوند. آزمایش مدل توسعه یافته با توجه به محدودیت زمان و بودجه است. و ارزیابی این موضوع که آیا نتیجه بدست آمده با اهداف اصلی کسبوکار همسو است یا خیر میتواند اطلاعات و الگوهای کشفشده ارزشمندی را استخراج نماید. موفقیت در این مرحله به تعامل تحلیلگران داده، تحلیلگران تجاری و تصمیم گیرندگان برای تفسیر صحیح الگوهای دانش است.
۶- پیاده سازی و استقرار
استقرار و پیاده سازی : حتی اگر هدف مدل داشتن یک اکتشاف ساده از دادهها باشد، دانش بهدستآمده از این اکتشاف باید به گونهای سازماندهی و ارائه شود که کاربر نهایی بتواند از آن استفاده کند. مرحله استقرار شامل فعالیت های تعمیر، نگهداری و نظارت برای جلوگیری از مشکلات در طول فاز عملیاتی (یا فاز پس از پروژه) است. از آنجا که همه چیز در مورد کسب و کار دائماً در حال تغییر است، داده هایی که منعکس کننده فعالیت های تجاری هستند نیز در حال تغییر هستند. با گذشت زمان، مدلها و دادههای قدیمی ممکن است منسوخ، نامربوط یا گمراهکننده شوند. نظارت و نگهداری مدل ها اهمیت زیادی دارد.











این پست دارای 2 نظر است
خیلی خوب توضیح دادید، مخصوصاً بخش آمادهسازی دادهها که تا ۸۰٪ زمان پروژه رو میگیره برام جالب بود.
ممنون از نظر شما! بله، مرحله پیشپردازش دادهها واقعاً زمانبره اما پایه و اساس موفقیت کل پروژه یادگیری ماشینه.