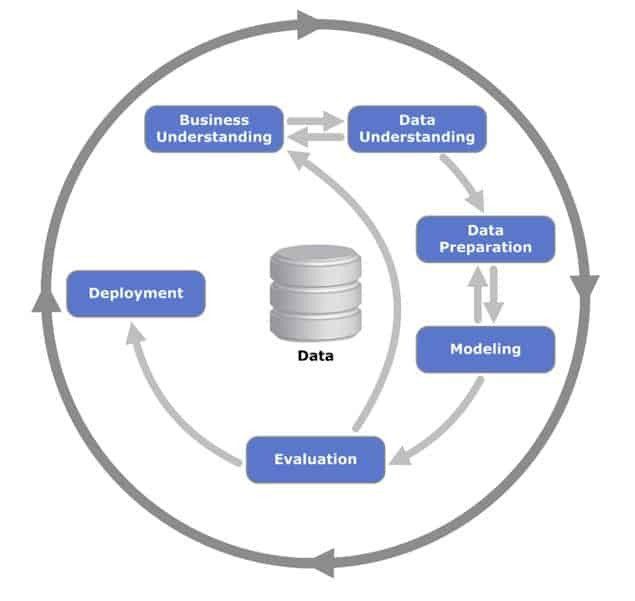
Get to know the CRISP cycle – nowadays, machine learning as one of the main needs of the industry has received much attention from managers and users. For the successful implementation of machine learning, its stages and steps must be followed correctly. In this section, the stages of successful implementation of machine learning are interpreted as the CRISP cycle.
CRISP cycle
1- Understanding business
2- Data understanding
3- Data preprocessing and preparation
4- Create a model
5- Testing and evaluating and getting feedback
6- Implementation and establishment
1- Understanding business
Understanding business requires managing new knowledge and clearly defining business goals. At this stage, we have to check the business conditions and analyze the competitors and customers’ behavior. And also the development team is responsible for data collection, data analysis.
2- Understanding the data
The main activity in the data mining process is to identify relevant data from existing databases. And we specify how to store the data. The analyst often uses a variety of statistical and graphical techniques to better understand the data. Data can be classified into two categories: quantitative and qualitative. Quantitative data is measured using numerical values or numerical data. It can be discrete and integer or continuous, which can be used as average, minimum and maximum, median and standard deviation. Qualitative data which are as categorical data and in the form of nominal and ordinal data.
3- Data preprocessing and preparation
In the stage of data preparation and pre-processing, the identified data are ready for analysis with data mining methods. In CRISP, data preprocessing takes the most time. Because in the business world, data is not clean, and up to 80% of data mining time is spent sorting and preparing it.
4- Create a model
Model creation: Creating a model includes evaluating, analyzing and comparing different models. Various modeling techniques can be applied to the pre-processed dataset. There is no best proposed model, but it is determined based on the evaluation and testing of models in order to achieve optimal results.
5- Testing and evaluating and getting feedback
– Testing, evaluating and getting feedback: At this stage, the developed models are evaluated in terms of accuracy and generality. Testing the developed model is due to time and budget constraints. And evaluating whether the result is aligned with the main business goals or not can extract valuable information and discovered patterns. Success at this stage depends on the interaction of data analysts, business analysts and decision makers to correctly interpret knowledge patterns.
6- Implementation and establishment
Deployment and implementation: Even if the goal of the model is to have a simple discovery of the data, the knowledge obtained from this discovery must be organized and presented in a way that the end user can use it. The deployment phase includes repair, maintenance, and monitoring activities to prevent problems during the operational phase (or post-project phase). Because everything about business is constantly changing, the data that reflects business activities is also changing. Over time, old models and data may become outdated, irrelevant, or misleading. Monitoring and maintenance of models is very important.