The concept of machine learning
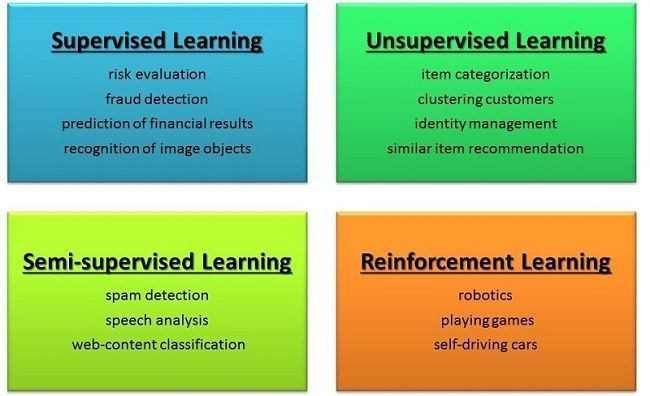
supervised learning
A variety of machine learning models, the learning process of the algorithm from the training data set can be considered as a teacher who supervises the learning process. We know the correct answers, the algorithm repeatedly predicts on the training data and is corrected by the teacher. Learning stops when the algorithm reaches an acceptable level of performance. In supervised learning, you provide explicit inputs to the machine learning algorithm. The algorithm knows what to learn from the data and what conclusions to expect from it. Data labeling is important for building a supervised model. Companies collect large data sets on a daily basis. Labeling these datasets to make the machine learning model easier to work with
(machine learning) Supervised learning algorithms attempt to model relationships and dependencies between output, target prediction, and input features so that we can predict new data output values based on those relationships learned from previous data sets.
Supervised learning can be further classified into regression and classification, which are applied to time series forecasting and recommender systems.
1- Regression related to time series whose output is continuous. The ultimate goal of the regression algorithm is to draw the best line or curve between the data. The three main metrics used to evaluate the trained regression model are variance, deviation, and error.
2- Classification, which outputs are grouped and discrete, and basically classifies a set of data into classes.
Some popular examples of supervised machine learning algorithms are:
Linear regression for regression problems.
Random forest for classification and regression problems.
Support vector machines for classification problems.

unsupervised learning
In unsupervised learning you only have access to the input data and no associated output variables. The goal of unsupervised learning is to model the structure or distribution of data in order to obtain and extract more information from the data. In unsupervised learning, unlike supervised learning, there are no right answers and no teacher. Algorithms act on their own to discover and provide structure in data.
Unsupervised learning algorithms are used for data clustering and association rules based on available features.
- Clustering: In clustering you want to discover groupings in the data, such as grouping customers by purchasing behavior.
- Association rules: You want to discover rules that describe large chunks of your data, such as people who buy product/service X also tend to buy product/service Y. Association rules allow you to create relationships between data objects in large databases. This technique is about discovering relationships between variables in databases.
Some popular examples of unsupervised learning algorithms are:
Hierarchical clustering
K-means clustering
K-NN (k nearest neighbor)
Principal component analysis
Single value decomposition
Independent component analysis

Hierarchical clustering
Hierarchical clustering is an algorithm that creates a hierarchy of clusters. It starts with all data assigned to a cluster. Here, two adjacent clusters are grouped into one cluster. This algorithm ends when only one cluster remains.
K-means
This type of K-means clustering starts with a fixed number of clusters. It assigns all the data to the number of clusters. This clustering method does not require the number of K clusters as input. This method reduces the number of clusters (per iteration) by merging the process by using the distance measure. Finally, we have a large cluster that contains all the objects.
K- Nearest neighbors
K-Nearest Neighbor is the simplest machine learning classifier. It differs from other machine learning techniques in that it does not generate a model. It is a simple algorithm that stores all existing instances and classifies new instances based on similarity criteria.
semi-supervised learning
Problems where you have a large amount of input data and only some of the data have labels are called semi-supervised learning. In fact, semi-supervised learning is between supervised and unsupervised learning. You can use unsupervised learning techniques to discover and learn structure in input variables. You can also use supervised learning techniques to make the best predictions for unlabeled data, feed that data back as training data to a supervised learning algorithm, and use the model to make predictions on new unlabeled data.
reinforcement learning
No machine learning algorithm is 100% accurate. The level of accuracy depends on the dataset you train the algorithm with. This means that after training an algorithm, new data sets will be available. These datasets may have the potential to significantly improve the accuracy of your model. You can use reinforcement learning for this type of scenario. Reinforcement learning is the concept of updating the algorithm during production. Reinforcement learning models can be retrained based on new inputs.
Unstructured data types
Many organizations today struggle to manage growing volumes of unstructured data. Machine learning gives the right structure and meaning to the data to help in decision making, investment and strategy setting.
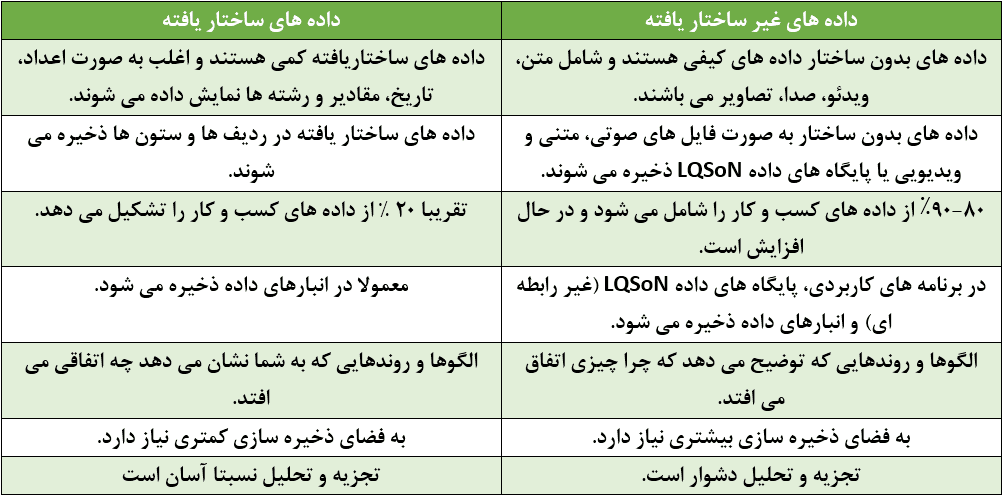
1- Structured data
2- Unstructured data
3- Semi-structured data
What is structured data?
Quantitative (numerical) structured data is highly organized and can be reviewed and analyzed using data analysis software. This type of data has an orderly design and is placed in rows, columns and tables. Structured data is great for basic organization and quantitative calculations, but lacks the flexibility needed to define parameters. And it can also not give more than enough to people.
What is unstructured data?
Unstructured data is information that does not have a specific organization and does not fit into a defined framework. Examples of unstructured data include: Audio, video, images and text types: Reports, emails, social media posts.
Finding insights in unstructured data is not easy, but when analyzed properly, textual data can be invaluable for extracting qualitative results, such as customer reviews, or organizing business data.

What is semi-structured data?
Semi-structured data refers to data that does not conform to a data model but has a structure. It is data that does not fit into a logical database, but has some organized characteristics that make it easier to analyze.
Characteristics of semi-structured data:
- Data does not conform to a data model but is structured.
- Data cannot be stored in a row and column format like a database
- Semi-structured data contains tags and elements that are used to group and describe how the data is stored.
- Similar entities are grouped together and organized into a hierarchy
- Entities in a group may or may not have the same attributes
- The size and type of the same features in a group may vary
- Due to its lack of structure, it cannot be easily used by computer programs. With some processes, we can store them in a relational database.
Keywords: machine learning, supervised learning, unsupervised learning, structured data, unstructured data, semi-structured data










